包下载地址
Centos rpm包下载:
https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/
具体文件为(以19.4.0为例子):
- 公共
- clickhouse-common-static-19.4.0-2.x86_64.rpm - clickhouse-common-static-dbg-19.4.0-2.x86_64.rpm - 客户端
- clickhouse-client-19.4.0-2.noarch.rpm - 服务端
- clickhouse-server-19.4.0-2.noarch.rpm - clickhouse-server-base-19.4.0-2.x86_64.rpm - clickhouse-server-common-19.4.0-2.noarch.rpm
分布式部署
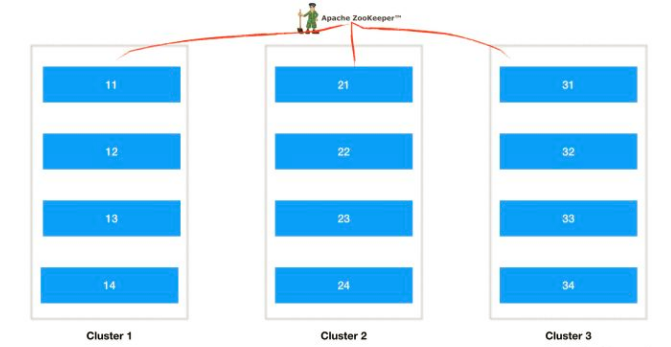
高可用说明
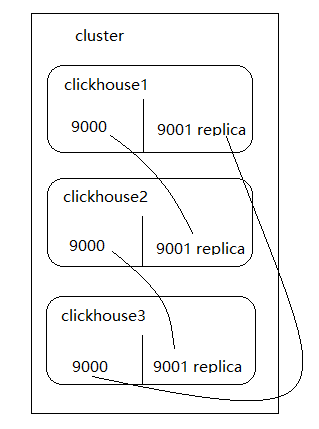
配置文件说明
<yandex>
<!-- 集群配置 -->
<clickhouse_remote_servers>
<bip_ck_cluster>
<!-- 数据分片1 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>yandex0</host>
<port>9000</port>
<user>default</user>
<password>admin123</password>
</replica>
<replica>
<host>yandex1</host>
<port>9001</port>
<user>default</user>
<password>admin123</password>
</replica>
</shard>
<!-- 数据分片2 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>yandex1</host>
<port>9000</port>
<user>default</user>
<password>admin123</password>
</replica>
<replica>
<host>yandex2</host>
<port>9001</port>
<user>default</user>
<password>admin123</password>
</replica>
</shard>
<!-- 数据分片3 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>yandex2</host>
<port>9000</port>
<user>default</user>
<password>admin123</password>
</replica>
<replica>
<host>yandex0</host>
<port>9001</port>
<user>default</user>
<password>admin123</password>
</replica>
</shard>
</bip_ck_cluster>
</clickhouse_remote_servers>
<!-- 本节点副本名称(这里无用) -->
<macros>
<replica>yandex0</replica>
</macros>
<!-- 监听网络(貌似重复) -->
<networks>
<ip>::/0</ip>
</networks>
<!-- ZK -->
<zookeeper-servers>
<node index="1">
<host>1.xxxx.sina.com.cn</host>
<port>2181</port>
</node>
<node index="2">
<host>2.xxxx.sina.com.cn</host>
<port>2181</port>
</node>
<node index="3">
<host>3.xxxxp.sina.com.cn</host>
<port>2181</port>
</node>
</zookeeper-servers>
<!-- 数据压缩算法 -->
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
双节点配置
容灾配置
服务器分为两台,每台启动一个实例,内存较大的负责于应用交互,内存较小的为备份节点。具体如下:
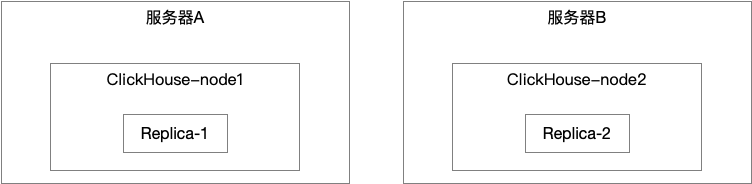
服务器假设:
- 操作系统:centos 7.2
- 服务器A的IP: 192.168.1.10 主机名: node1
- 服务器B的IP: 192.168.1.11 主机名: node2
- Clickhouse安装是以root用户进行安装, clickhouse用户进行启动运行实例。
- 文件存储路径/home/clickhouse/database/ 为跟路径(/home/clickhouse 可用空间必须大于500G以上)
- Zookeeper more为一个节点 地址为:192.168.1.10
配置文件信息
服务器A 配置文件
<yandex>
<clickhouse_remote_servers>
<cluster_maple>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node1</host>
<port>9000</port>
</replica>
<replica>
<host>node2</host>
<port>9000</port>
</replica>
</shard>
</cluster_maple>
</clickhouse_remote_servers>
<zookeeper-servers>
<node index="1">
<host>192.168.1.10</host>
<port>2181</port>
</node>
</zookeeper-servers> <!-- 数据压缩算法 -->
<macros>
<layer>cluster_maple</layer>
<shard>01</shard>
<replica>cluster_maple-01-01</replica>
</macros>
<networks>
<ip>::/0</ip>
</networks>
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
服务器B 配置文件
<yandex>
<clickhouse_remote_servers>
<cluster_maple>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node1</host>
<port>9000</port>
</replica>
<replica>
<host>node2</host>
<port>9000</port>
</replica>
</shard>
</cluster_maple>
</clickhouse_remote_servers>
<zookeeper-servers>
<node index="1">
<host>192.168.1.10</host>
<port>2181</port>
</node>
</zookeeper-servers> <!-- 数据压缩算法 -->
<macros>
<layer>cluster_maple</layer>
<shard>01</shard>
<replica>cluster_maple-01-02</replica>
</macros>
<networks>
<ip>::/0</ip>
</networks>
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
用户配置文件-共用
<?xml version="1.0"?>
<yandex>
<!-- Profiles of settings. -->
<profiles>
<!-- Default settings. -->
<default>
<!-- Maximum memory usage for processing single query, in bytes. -->
<max_memory_usage>10000000000</max_memory_usage>
<!-- Use cache of uncompressed blocks of data. Meaningful only for processing many of very short queries. -->
<use_uncompressed_cache>0</use_uncompressed_cache>
<!-- How to choose between replicas during distributed query processing.
random - choose random replica from set of replicas with minimum number of errors
nearest_hostname - from set of replicas with minimum number of errors, choose replica
with minimum number of different symbols between replica's hostname and local hostname
(Hamming distance).
in_order - first live replica is chosen in specified order.
-->
<load_balancing>random</load_balancing>
</default>
<!-- Profile that allows only read queries. -->
<readonly>
<readonly>1</readonly>
</readonly>
</profiles>
<!-- Users and ACL. -->
<users>
<!-- If user name was not specified, 'default' user is used. -->
<default>
<!-- Password could be specified in plaintext or in SHA256 (in hex format).
If you want to specify password in plaintext (not recommended), place it in 'password' element.
Example: <password>qwerty</password>.
Password could be empty.
If you want to specify SHA256, place it in 'password_sha256_hex' element.
Example: <password_sha256_hex>65e84be33532fb784c48129675f9eff3a682b27168c0ea744b2cf58ee02337c5</password_sha256_hex>
How to generate decent password:
Execute: PASSWORD=$(base64 < /dev/urandom | head -c8); echo "$PASSWORD"; echo -n "$PASSWORD" | sha256sum | tr -d '-'
In first line will be password and in second - corresponding SHA256.
-->
<password>maple@123</password>
<!-- List of networks with open access.
To open access from everywhere, specify:
<ip>::/0</ip>
To open access only from localhost, specify:
<ip>::1</ip>
<ip>127.0.0.1</ip>
Each element of list has one of the following forms:
<ip> IP-address or network mask. Examples: 213.180.204.3 or 10.0.0.1/8 or 10.0.0.1/255.255.255.0
2a02:6b8::3 or 2a02:6b8::3/64 or 2a02:6b8::3/ffff:ffff:ffff:ffff::.
<host> Hostname. Example: server01.yandex.ru.
To check access, DNS query is performed, and all received addresses compared to peer address.
<host_regexp> Regular expression for host names. Example, ^server\d\d-\d\d-\d\.yandex\.ru$
To check access, DNS PTR query is performed for peer address and then regexp is applied.
Then, for result of PTR query, another DNS query is performed and all received addresses compared to peer address.
Strongly recommended that regexp is ends with $
All results of DNS requests are cached till server restart.
-->
<networks incl="networks" replace="replace">
<ip>::/0</ip>
</networks>
<!-- Settings profile for user. -->
<profile>default</profile>
<!-- Quota for user. -->
<quota>default</quota>
</default>
<!-- Example of user with readonly access. -->
<readonly>
<password></password>
<networks incl="networks" replace="replace">
<ip>::1</ip>
<ip>127.0.0.1</ip>
</networks>
<profile>readonly</profile>
<quota>default</quota>
</readonly>
</users>
<!-- Quotas. -->
<quotas>
<!-- Name of quota. -->
<default>
<!-- Limits for time interval. You could specify many intervals with different limits. -->
<interval>
<!-- Length of interval. -->
<duration>3600</duration>
<!-- No limits. Just calculate resource usage for time interval. -->
<queries>0</queries>
<errors>0</errors>
<result_rows>0</result_rows>
<read_rows>0</read_rows>
<execution_time>0</execution_time>
</interval>
</default>
</quotas>
</yandex>
服务器A主配置文件-config.xml
<?xml version="1.0"?>
<!--
NOTE: User and query level settings are set up in "users.xml" file.
-->
<yandex>
<logger>
<!-- Possible levels: https://github.com/pocoproject/poco/blob/develop/Foundation/include/Poco/Logger.h#L105 -->
<level>trace</level>
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
<size>1000M</size>
<count>10</count>
<!-- <console>1</console> --> <!-- Default behavior is autodetection (log to console if not daemon mode and is tty) -->
</logger>
<!--display_name>production</display_name--> <!-- It is the name that will be shown in the client -->
<http_port>8123</http_port>
<tcp_port>9000</tcp_port>
<!-- For HTTPS and SSL over native protocol. -->
<!--
<https_port>8443</https_port>
<tcp_port_secure>9440</tcp_port_secure>
-->
<!-- Used with https_port and tcp_port_secure. Full ssl options list: https://github.com/ClickHouse-Extras/poco/blob/master/NetSSL_OpenSSL/include/Poco/Net/SSLManager.h#L71 -->
<openSSL>
<server> <!-- Used for https server AND secure tcp port -->
<!-- openssl req -subj "/CN=localhost" -new -newkey rsa:2048 -days 365 -nodes -x509 -keyout /etc/clickhouse-server/server.key -out /etc/clickhouse-server/server.crt -->
<certificateFile>/etc/clickhouse-server/server.crt</certificateFile>
<privateKeyFile>/etc/clickhouse-server/server.key</privateKeyFile>
<!-- openssl dhparam -out /etc/clickhouse-server/dhparam.pem 4096 -->
<dhParamsFile>/etc/clickhouse-server/dhparam.pem</dhParamsFile>
<verificationMode>none</verificationMode>
<loadDefaultCAFile>true</loadDefaultCAFile>
<cacheSessions>true</cacheSessions>
<disableProtocols>sslv2,sslv3</disableProtocols>
<preferServerCiphers>true</preferServerCiphers>
</server>
<client> <!-- Used for connecting to https dictionary source -->
<loadDefaultCAFile>true</loadDefaultCAFile>
<cacheSessions>true</cacheSessions>
<disableProtocols>sslv2,sslv3</disableProtocols>
<preferServerCiphers>true</preferServerCiphers>
<!-- Use for self-signed: <verificationMode>none</verificationMode> -->
<invalidCertificateHandler>
<!-- Use for self-signed: <name>AcceptCertificateHandler</name> -->
<name>RejectCertificateHandler</name>
</invalidCertificateHandler>
</client>
</openSSL>
<!-- Default root page on http[s] server. For example load UI from https://tabix.io/ when opening http://localhost:8123 -->
<!--
<http_server_default_response><![CDATA[<html ng-app="SMI2"><head><base href="http://ui.tabix.io/"></head><body><div ui-view="" class="content-ui"></div><script src="http://loader.tabix.io/master.js"></script></body></html>]]></http_server_default_response>
-->
<!-- Port for communication between replicas. Used for data exchange. -->
<interserver_http_port>9009</interserver_http_port>
<!-- Hostname that is used by other replicas to request this server.
If not specified, than it is determined analoguous to 'hostname -f' command.
This setting could be used to switch replication to another network interface.
-->
<!--
<interserver_http_host>example.yandex.ru</interserver_http_host>
-->
<interserver_http_host>[服务器IP]</interserver_http_host>
<!-- Listen specified host. use :: (wildcard IPv6 address), if you want to accept connections both with IPv4 and IPv6 from everywhere. -->
<!-- <listen_host>::</listen_host> -->
<!-- Same for hosts with disabled ipv6: -->
<!-- <listen_host>0.0.0.0</listen_host> -->
<!-- Default values - try listen localhost on ipv4 and ipv6: -->
<!--
<listen_host>::1</listen_host>
<listen_host>127.0.0.1</listen_host>
-->
<listen_host>0.0.0.0</listen_host>
<!-- Don't exit if ipv6 or ipv4 unavailable, but listen_host with this protocol specified -->
<!-- <listen_try>0</listen_try> -->
<!-- Allow listen on same address:port -->
<!-- <listen_reuse_port>0</listen_reuse_port> -->
<!-- <listen_backlog>64</listen_backlog> -->
<max_connections>4096</max_connections>
<keep_alive_timeout>3</keep_alive_timeout>
<!-- Maximum number of concurrent queries. -->
<max_concurrent_queries>100</max_concurrent_queries>
<!-- Set limit on number of open files (default: maximum). This setting makes sense on Mac OS X because getrlimit() fails to retrieve
correct maximum value. -->
<!-- <max_open_files>262144</max_open_files> -->
<!-- Size of cache of uncompressed blocks of data, used in tables of MergeTree family.
In bytes. Cache is single for server. Memory is allocated only on demand.
Cache is used when 'use_uncompressed_cache' user setting turned on (off by default).
Uncompressed cache is advantageous only for very short queries and in rare cases.
-->
<uncompressed_cache_size>8589934592</uncompressed_cache_size>
<!-- Approximate size of mark cache, used in tables of MergeTree family.
In bytes. Cache is single for server. Memory is allocated only on demand.
You should not lower this value.
-->
<mark_cache_size>5368709120</mark_cache_size>
<!-- Path to data directory, with trailing slash. -->
<path>/home/clickhouse/database/lib/clickhouse/</path>
<!-- Path to temporary data for processing hard queries. -->
<tmp_path>/home/clickhouse/database/lib/clickhouse/tmp/</tmp_path>
<!-- Directory with user provided files that are accessible by 'file' table function. -->
<user_files_path>/home/clickhouse/database/lib/clickhouse/user_files/</user_files_path>
<!-- Path to configuration file with users, access rights, profiles of settings, quotas. -->
<users_config>users.xml</users_config>
<!-- Default profile of settings. -->
<default_profile>default</default_profile>
<!-- System profile of settings. This settings are used by internal processes (Buffer storage, Distibuted DDL worker and so on). -->
<!-- <system_profile>default</system_profile> -->
<!-- Default database. -->
<default_database>default</default_database>
<!-- Server time zone could be set here.
Time zone is used when converting between String and DateTime types,
when printing DateTime in text formats and parsing DateTime from text,
it is used in date and time related functions, if specific time zone was not passed as an argument.
Time zone is specified as identifier from IANA time zone database, like UTC or Africa/Abidjan.
If not specified, system time zone at server startup is used.
Please note, that server could display time zone alias instead of specified name.
Example: W-SU is an alias for Europe/Moscow and Zulu is an alias for UTC.
-->
<!-- <timezone>Europe/Moscow</timezone> -->
<!-- You can specify umask here (see "man umask"). Server will apply it on startup.
Number is always parsed as octal. Default umask is 027 (other users cannot read logs, data files, etc; group can only read).
-->
<!-- <umask>022</umask> -->
<!-- Perform mlockall after startup to lower first queries latency
and to prevent clickhouse executable from being paged out under high IO load.
Enabling this option is recommended but will lead to increased startup time for up to a few seconds.
-->
<mlock_executable>false</mlock_executable>
<!-- Configuration of clusters that could be used in Distributed tables.
https://clickhouse.yandex/docs/en/table_engines/distributed/
-->
<remote_servers >
<!-- Test only shard config for testing distributed storage -->
</remote_servers>
<!-- If element has 'incl' attribute, then for it's value will be used corresponding substitution from another file.
By default, path to file with substitutions is /etc/metrika.xml. It could be changed in config in 'include_from' element.
Values for substitutions are specified in /yandex/name_of_substitution elements in that file.
-->
<!-- ZooKeeper is used to store metadata about replicas, when using Replicated tables.
Optional. If you don't use replicated tables, you could omit that.
See https://clickhouse.yandex/docs/en/table_engines/replication/
-->
<zookeeper>
</zookeeper>
<!-- Substitutions for parameters of replicated tables.
Optional. If you don't use replicated tables, you could omit that.
See https://clickhouse.yandex/docs/en/table_engines/replication/#creating-replicated-tables
-->
<macros incl="macros" optional="true" />
<!-- Reloading interval for embedded dictionaries, in seconds. Default: 3600. -->
<builtin_dictionaries_reload_interval>3600</builtin_dictionaries_reload_interval>
<!-- Maximum session timeout, in seconds. Default: 3600. -->
<max_session_timeout>3600</max_session_timeout>
<!-- Default session timeout, in seconds. Default: 60. -->
<default_session_timeout>60</default_session_timeout>
<!-- Sending data to Graphite for monitoring. Several sections can be defined. -->
<!--
interval - send every X second
root_path - prefix for keys
hostname_in_path - append hostname to root_path (default = true)
metrics - send data from table system.metrics
events - send data from table system.events
asynchronous_metrics - send data from table system.asynchronous_metrics
-->
<!--
<graphite>
<host>localhost</host>
<port>42000</port>
<timeout>0.1</timeout>
<interval>60</interval>
<root_path>one_min</root_path>
<hostname_in_path>true</hostname_in_path>
<metrics>true</metrics>
<events>true</events>
<asynchronous_metrics>true</asynchronous_metrics>
</graphite>
<graphite>
<host>localhost</host>
<port>42000</port>
<timeout>0.1</timeout>
<interval>1</interval>
<root_path>one_sec</root_path>
<metrics>true</metrics>
<events>true</events>
<asynchronous_metrics>false</asynchronous_metrics>
</graphite>
-->
<!-- Query log. Used only for queries with setting log_queries = 1. -->
<query_log>
<!-- What table to insert data. If table is not exist, it will be created.
When query log structure is changed after system update,
then old table will be renamed and new table will be created automatically.
-->
<database>system</database>
<table>query_log</table>
<!--
PARTITION BY expr https://clickhouse.yandex/docs/en/table_engines/custom_partitioning_key/
Example:
event_date
toMonday(event_date)
toYYYYMM(event_date)
toStartOfHour(event_time)
-->
<partition_by>toYYYYMM(event_date)</partition_by>
<!-- Interval of flushing data. -->
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_log>
<!-- Query thread log. Has information about all threads participated in query execution.
Used only for queries with setting log_query_threads = 1. -->
<query_thread_log>
<database>system</database>
<table>query_thread_log</table>
<partition_by>toYYYYMM(event_date)</partition_by>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_thread_log>
<!-- Uncomment if use part log.
Part log contains information about all actions with parts in MergeTree tables (creation, deletion, merges, downloads).
<part_log>
<database>system</database>
<table>part_log</table>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</part_log>
-->
<!-- Parameters for embedded dictionaries, used in Yandex.Metrica.
See https://clickhouse.yandex/docs/en/dicts/internal_dicts/
-->
<!-- Path to file with region hierarchy. -->
<!-- <path_to_regions_hierarchy_file>/opt/geo/regions_hierarchy.txt</path_to_regions_hierarchy_file> -->
<!-- Path to directory with files containing names of regions -->
<!-- <path_to_regions_names_files>/opt/geo/</path_to_regions_names_files> -->
<!-- Configuration of external dictionaries. See:
https://clickhouse.yandex/docs/en/dicts/external_dicts/
-->
<dictionaries_config>*_dictionary.xml</dictionaries_config>
<!-- Uncomment if you want data to be compressed 30-100% better.
Don't do that if you just started using ClickHouse.
-->
<compression incl="clickhouse_compression">
<!--
<!- - Set of variants. Checked in order. Last matching case wins. If nothing matches, lz4 will be used. - ->
<case>
<!- - Conditions. All must be satisfied. Some conditions may be omitted. - ->
<min_part_size>10000000000</min_part_size> <!- - Min part size in bytes. - ->
<min_part_size_ratio>0.01</min_part_size_ratio> <!- - Min size of part relative to whole table size. - ->
<!- - What compression method to use. - ->
<method>zstd</method>
</case>
-->
</compression>
<!-- Allow to execute distributed DDL queries (CREATE, DROP, ALTER, RENAME) on cluster.
Works only if ZooKeeper is enabled. Comment it if such functionality isn't required. -->
<distributed_ddl>
<!-- Path in ZooKeeper to queue with DDL queries -->
<path>/clickhouse/task_queue/ddl</path>
<!-- Settings from this profile will be used to execute DDL queries -->
<!-- <profile>default</profile> -->
</distributed_ddl>
<!-- Settings to fine tune MergeTree tables. See documentation in source code, in MergeTreeSettings.h -->
<!--
<merge_tree>
<max_suspicious_broken_parts>5</max_suspicious_broken_parts>
</merge_tree>
-->
<!-- Protection from accidental DROP.
If size of a MergeTree table is greater than max_table_size_to_drop (in bytes) than table could not be dropped with any DROP query.
If you want do delete one table and don't want to restart clickhouse-server, you could create special file <clickhouse-path>/flags/force_drop_table and make DROP once.
By default max_table_size_to_drop is 50GB; max_table_size_to_drop=0 allows to DROP any tables.
The same for max_partition_size_to_drop.
Uncomment to disable protection.
-->
<!-- <max_table_size_to_drop>0</max_table_size_to_drop> -->
<!-- <max_partition_size_to_drop>0</max_partition_size_to_drop> -->
<!-- Example of parameters for GraphiteMergeTree table engine -->
<graphite_rollup_example>
<pattern>
<regexp>click_cost</regexp>
<function>any</function>
<retention>
<age>0</age>
<precision>3600</precision>
</retention>
<retention>
<age>86400</age>
<precision>60</precision>
</retention>
</pattern>
<default>
<function>max</function>
<retention>
<age>0</age>
<precision>60</precision>
</retention>
<retention>
<age>3600</age>
<precision>300</precision>
</retention>
<retention>
<age>86400</age>
<precision>3600</precision>
</retention>
</default>
</graphite_rollup_example>
<!-- Directory in <clickhouse-path> containing schema files for various input formats.
The directory will be created if it doesn't exist.
-->
<format_schema_path>/home/clickhouse/database/lib/clickhouse/format_schemas/</format_schema_path>
<!-- Uncomment to disable ClickHouse internal DNS caching. -->
<!-- <disable_internal_dns_cache>1</disable_internal_dns_cache> -->
</yandex>
安装步骤
- 下载相关的rpm包
- 将安装包放在同一个文件夹下(如: /root/clickhouse)
cd /root/clickhouserpm -ivh --force *.rpm- 复制相关配置文件到
/etc/clickhouse-server/下(覆盖前请备份配置文件)。 - 创建clickhouse 用户
- 使用命令启动clickhouse:
systemctl start clickhouse-server - 检查是否启动成功
systemctl status clickhouse-server - 如果错误请查阅错误日志
tail -1000f /var/log/clickhouse-server/clickhouse-server.err.log
安装校验
- 执行
clickhouse-client -h 192.168.1.10 - 然后执行SQL
select * from system.clusters查询是否存在名为:cluster_maple,且数量为两条,shard_num 都为1,replica_num 分别为 1 2,host地址分别对应服务A与服务B的IP地址。
你这个不对吧,
每个节点的配置文件中的layer-shard居然是一样的.
首先这是单分片双副本的配置。
同一个{layer}-{shard}下面的表互为备份,会自动同步
每个节点的replica不一样是为了识别是哪个副本。