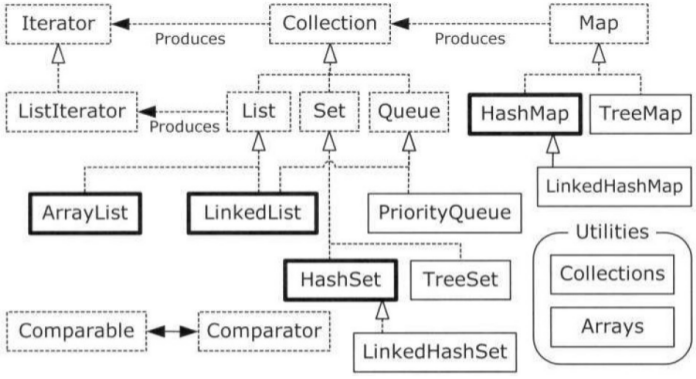
java中的容器主要分为三种:长度(大小)固定的Array(即数组)、不固定长度的Collection与Map。
我们使用容器管理一组数据,所谓的“管理”,便是增删改查、遍历,以及获取一些特征数据(比如最大值等)(不仅要能做到,还要效率高),那么根据不同的需求,选择不同的容器类(底层由不同的数据结构来支持)。
不管容器类底层什么实现,其实就三种,数组,链表和树。进而,容器类每次add时,必须要有机制确定数据存放在底层结构的哪个位置:
- 根据加入的先后,比如list
- hashcode方式,比如hashset,hashmap
- 根据元素本身的大小,比如treeset和treemap
我觉得背概念害死人,以这个角度来划分容器类,更顺一些。从另外一个维度讲,collection存储的基本单位是元素,map存储的基本单位是键值对。
当学到set的时候,其实我就很困惑,为什么hashset底层是用hashmap来实现的,用一个数组来实现不好么?其实反过来想一下,如果这样做,hashset还跟arraylist有什么不同?回想我的程序中用到ArrayList的地方,我难道真的关心元素存储的先后顺序么?这时候,用linkedhashset是不是效率更高呢?
Array 和 Arrays
Array就是数组,也就是长度固定的容器,一但创建了这个对象就不能改变其大小(capacity)。 Arrays是Array的工具类,其静态方法定义了对Array的各种操作,例如asList,binarySearch,equals(判断两个数组是否相等)
Collection和 Collections
Collection是线性数据类型的根接口,定义了最基本的操作(增、删、改、查、取得iterator、转化为数组等)。Collections是Collection的工具类,定义了对Collection的常用操作,比如max,binarySearch,synchronizedCollection。
LIST
可以取得List特有的ListIterator.ListIterator是Iterator的子接口,它与Iterator相似,但提供了向前移动能力(Iterator只能向后移动) ArrayList使用线性存储结构(数据结构中叫线性表),它的随机访问速度较快(因为它的底层是数组,可以通过数组的index直接找到元素),但插入或删除数据的速度较慢.
LinkedList使用链式存储结构(数据结构中叫链表,sun jdk1.6中使用的是双向链表,其内每个对象除了数据本身外,还有两个引用,分别指向前一个元素和后一个元素),它的随机访问速度较慢(需要从第一个元素开始向下或向上遍历,直到找到特定元素),但插入或删除速度较快。另外LinkedList可以直接实现queue或stack,因为它已经封装了相应的方法。
Vector与ArrayList相似,但它的操作是线程安全的,所以一般用于多线程情况下。
SET
Set与List相似,但Set中的元素不能重复。对象存储的位置跟添加的先后没有关系(也就是不支持按索引检索对象)。
HashSet通过使用哈希算法,查找速度较快(底层数据结构为HashMap)。 TreeSet保存的元素是经过排序的(根据TreeMap实现,底层数据结构为红黑树)。LinkedHashSet使用哈希算法保证查找速度,它以元素的插入顺序保存元素(底层数据结构为LinkedHashMap)。
QUEUE
Queue 因为LinkedList已经实现了Queue行为的方法,所以可以将一个LinkedList转化为Queue:
Queue<Integer> queue = new LinkedList<Integer>()�0�2Queue是先进行出的,而PriorityQueue通过设置优先级以使需要的元素”先出”.
iterator
屏蔽掉底层的数据结构,提供统一的遍历接口,其声明了如下方法:hasnext(),next()
Map ##
存储的是key value对